Forward Error Correction (FEC) IP
3GPP Compliant Forward Error Correction (FEC)
- Our 5G NR LDPC solution delivers market-leading performance and efficiency, providing a complete encoder and decoder IP suite for the 5G physical layer. Meticulously engineered to meet and exceed all 3GPP throughput and error correction criteria, it represents a critical component for next-generation wireless communication system.
- What truly sets our solution apart is its flexible software-defined architecture. This flexible IP is uniquely designed to run on a wide range of commercial off-the-shelf (COTS) Nvidia GPUs, from high-end data center accelerators to low-cost consumer gaming GeForce RTX cards.
- This dramatically reduces hardware costs and development time, enabling rapid deployment of powerful and scalable 5G solutions without the need for specialized ASICs, FPGAs or expensive high-end GPUs.

5G NR Tx/Rx Shared Channel Chains

In the intricate architecture of 5G New Radio (NR), ensuring data integrity during high-speed transmission is paramount. This is the critical role of Forward Error Correction (FEC), a sophisticated set of channel coding techniques designed to detect and correct transmission errors on the fly. By proactively adding redundant “parity” bits to the data before it’s sent over the airwaves, 5G networks can overcome signal noise and interference, drastically reducing the need for retransmissions and ensuring the low latency and high reliability that define the standard.
Unlike previous generations of wireless technology that primarily relied on Turbo and Convolutional codes, 5G NR adopts a strategic split approach, utilizing two different state-of-the-art FEC schemes for distinct purposes: Low-Density Parity-Check (LDPC) codes and Polar codes.
LDPC Codes: The Workhorse for High-Speed Data
Low-Density Parity-Check (LDPC) codes are the primary FEC mechanism for all user data in 5G.
They are applied to the data-carrying physical channels:
- Physical Downlink Shared Channel (PDSCH): Carries all user data from the base station (gNB) to the user device (UE).
- Physical Uplink Shared Channel (PUSCH): Carries all user data from the UEs to the gNB.
Why LDPC was chosen for data:
The selection of LDPC for the Enhanced Mobile Broadband (eMBB) use case was driven by its exceptional performance characteristics for large data blocks.
High Throughput: The structure of LDPC codes allows for highly parallelizable decoding algorithms.
This means that a large block of data can be processed simultaneously by multiple hardware units,
making it ideal for the high-throughput, multi-gigabit speeds promised by 5G.
Capacity-Approaching Performance: LDPC codes are renowned for their ability to perform very
close to the Shannon Limit—the theoretical maximum rate of error-free data transmission over a noisy channel.
This translates to highly efficient use of the available radio spectrum.
Scalability: The 3GPP standard defines a flexible and rate-compatible LDPC framework.
It uses two base graphs—one optimized for smaller transport blocks and another for larger
ones—that can be adapted to a wide variety of code rates and block sizes, providing scalability
for different network conditions and service requirements.


5G NR LDPC Codec and Rate Matching Suite
Our solution delivers a complete implementation of the LDPC codec (encoder and decoder) and rate matching/recovery functions as defined in 3GPP TS 38.212, fully optimized for the demands of 5G NR physical layer processing.
Key Features
- Standards-Compliant LDPC Codec
- Full LDPC Codec Implementation
- Compliant with 3GPP TS 38.212
- Supports Base Graphs BG1 and BG2
- Supports all Code rates and Block sizes corresponding to possible lifting sizes
- Rate Matching and Recovery
- Complete support for puncturing, repetition, and shortening
- Fully integrated with HARQ buffer management
- Supports up to 16 HARQ processes and 64 user pers HARQ ID (configurable)
- Full LDPC Codec Implementation
- CUDA-C Implementation for GPUs
Designed and optimized for NVIDIA GPUs, including low-cost RTX gaming GPUs. Scalable and highly configurable across GPU generations.
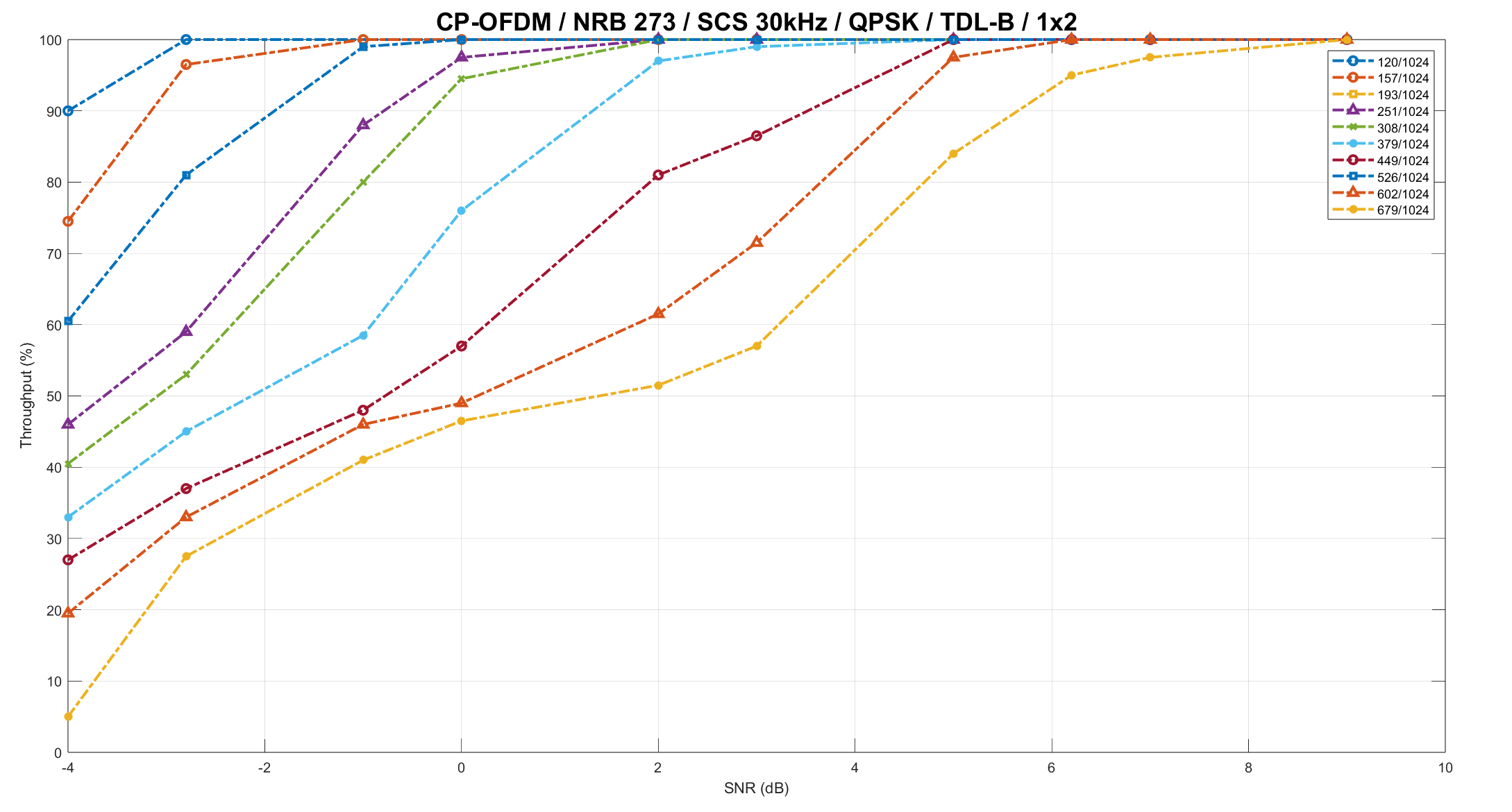
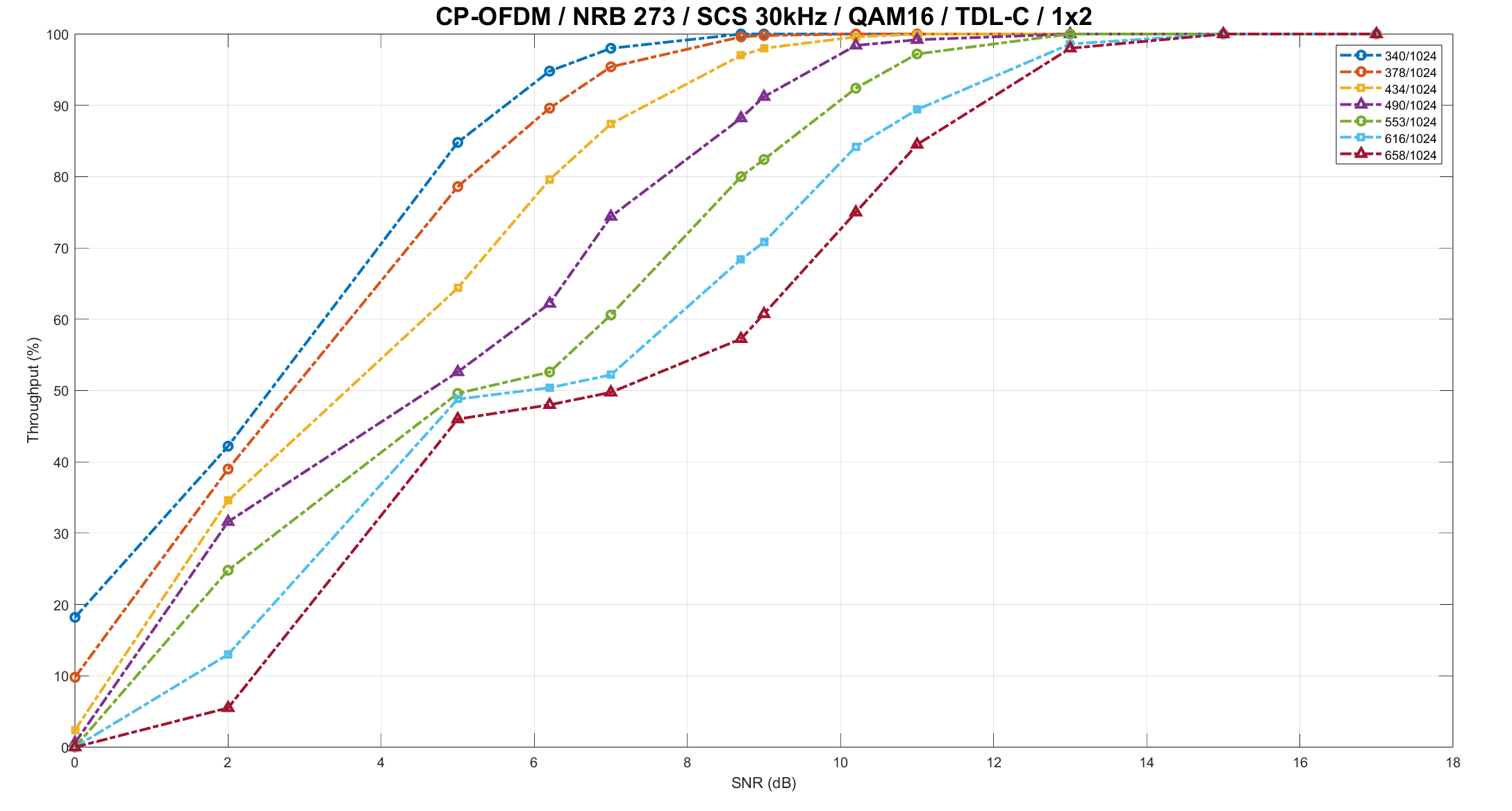
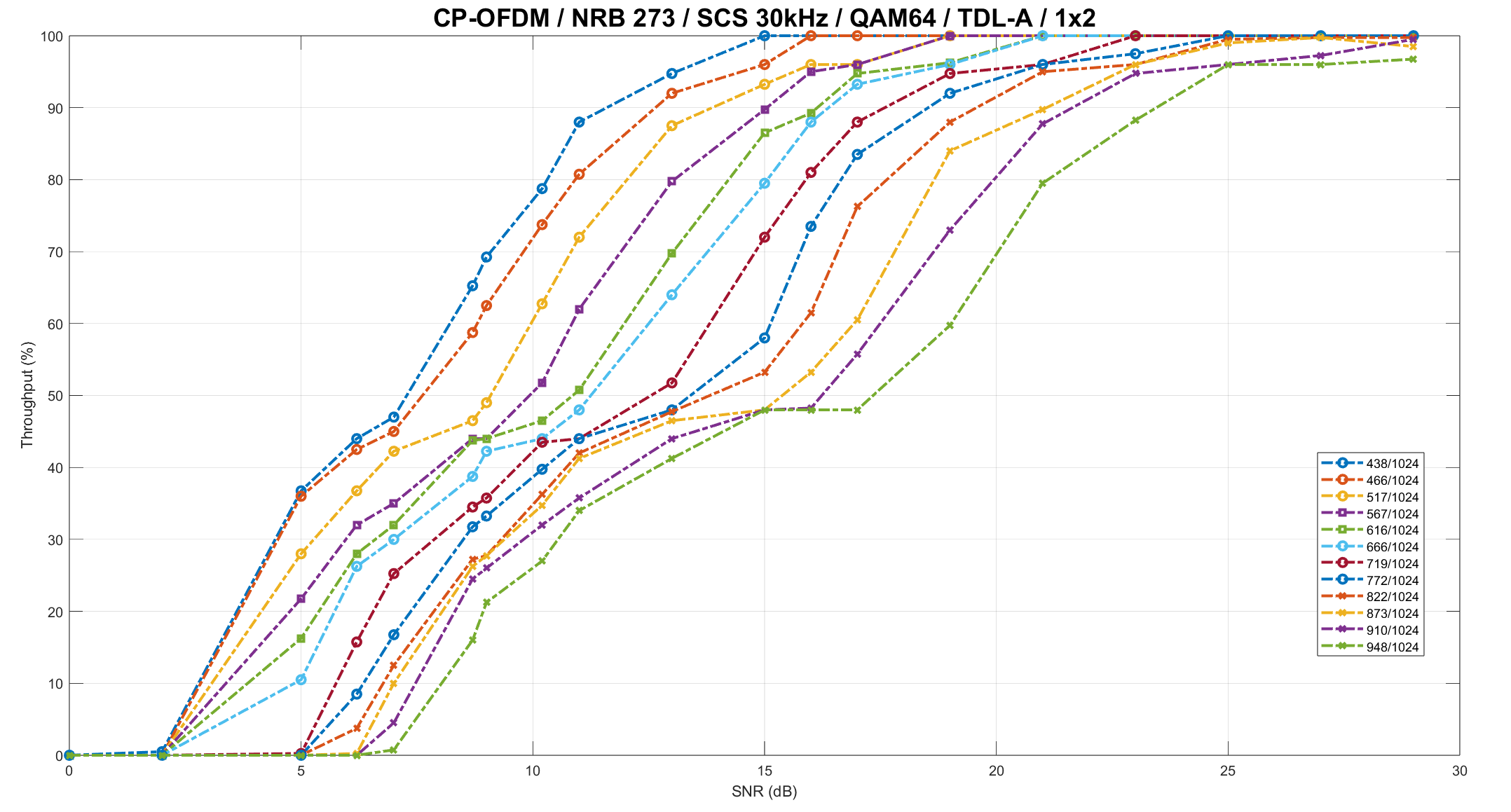
- Superior BLER Performance
Achieves improved BLER performance over generic decoder implementations. Demonstrated via detailed simulation plots and throughput analysis as per 38.214 – Table 5.1.3.1-1: MCS index table.
- Fully Integrated HARQ Management
Includes complete HARQ soft buffer management internal to the GPU, minimizing PCIe overhead and maximizing throughput in real-time systems.
- Flexible and Easy Integration
Provides a standards-aligned FEC API for smooth integration into existing 5G L1. Designed for modularity and rapid deployment.
- Comprehensive FEC Stats and Logging, Memory Usage Stats and Safety Memguard Mechanism for host and device memories.